News & Insights
Using AI to track open source climate clause adoption



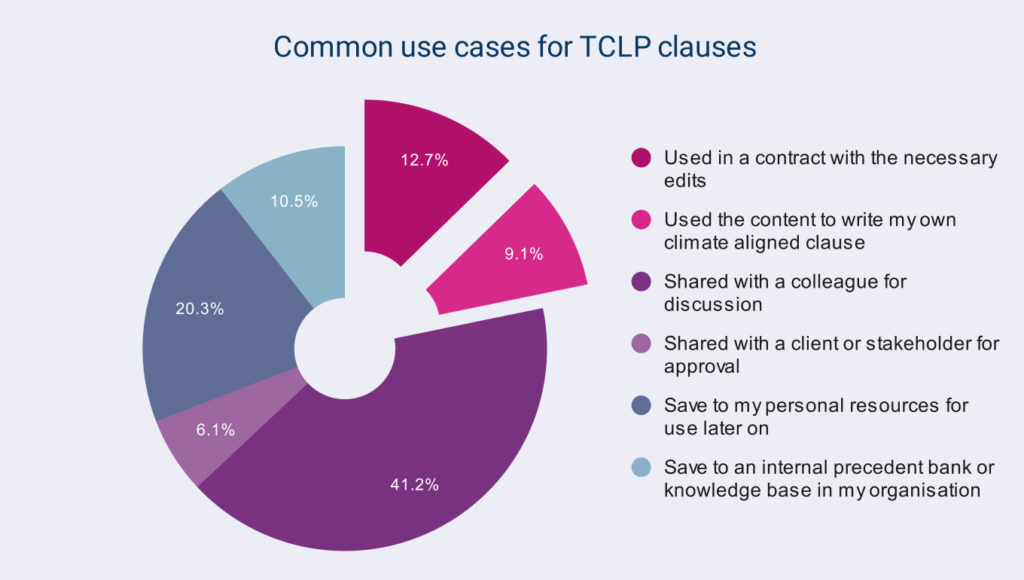
Summary
We often think of innovation as a space to create something new without constraints, that points us towards to a future of what’s possible and where we can go next. But innovation can also be used in a different direction; to help us make sense of the past so we can better understand what we’ve already done. This is easy to forget, especially when thinking about novel technologies.
In late 2024, we ran a six-week innovation sprint to explore how AI might help identify where our clauses—or content inspired by them—appear in legal documents. This is a significant challenge for us as an organisation as while our clauses are freely available and accessed by thousands globally, we have no effective way to track their adoption and impact.
In addressing this challenge, we developed a tool with two key features: a clause detector that could identify TCLP language in contracts with 94% accuracy, and a clause recommender that could suggest relevant climate clauses for specific contracts. The project achieved significant efficiency gains, analysing thousands of documents in minutes rather than the countless hours manual review would require.
This project was kindly awarded by one our funders, The Quadrature Climate Foundation, in collaboration with Faculty’s fellowship programme.
Please mind the jargon: Machine learning is a complex field with its own language and many nuances. We have tried our best to include simple explanations of more technical areas in the hope that it gives you enough context to understand our work. That said, the explanations are simplified and will not always cover the whole scope of a given topic.
Background and context
Why tracking our content matters
Since 2019, our organisation has published open source legal content that enables professionals across all sectors to take climate-aligned approaches in contracts and decision-making.
But despite wide dissemination, understanding the actual uptake of this content—especially within commercial legal documents—has been a persistent challenge.
Knowing where and how our clauses are used helps us assess impact, iterate on content, and build trust with partners and funders. However, manually identifying clauses would require countless hours of painstaking effort and is not feasible at scale, especially when they are adapted, paraphrased, or embedded deep within long contracts. That’s where artificial intelligence offers a promising path forward. By using NLP, thousands of documents can be processed and scanned in less than a minute.
Our content is primed to be tracked
Our resources share key characteristics that make them particularly promising for Natural Language Processing (NLP) applications:
- They are all purely text based and do not require diagrams, calculations or other assets to complete their meaning.
- They are freely available through our website and accessed by thousands of people globally each week.
Primary objectives
The project focused on one high-value question:
How might we use AI to identify and evidence where our content is being used?
Specific sub-goals included:
- Train a model to automatically detect TCLP clauses or TCLP-inspired language in a single contract
- Develop a system that deploys this model on large volumes of contracts efficiently
- Create a user-friendly interface for non-technical users
Data collection, preparation, and synthetic creation
Armed with step one—training a model—we reached our first hurdle. As is too often the case for data scientists, we found ourselves without sufficient data.
What does “training a model” mean?
A core tenet in data science is using statistics to make sense of information. Machine learning models, in a way, are like big pattern-finding machines that use math to make predictions.
When we talk about training a model, we mean helping it figure out which patterns matter, how much they matter, and in what order to use them to get the best results.
This process mimics the way humans learn. Let’s use a very simple example to illustrate:
- You are in a room with three light switches.
- In the room next door, there are three lightbulbs.
- You need to figure out which light switch belongs to which lightbulb.
So what do you do? Well, you probably would flip the switches one by one, going into the room next door each time to see which lightbulb was turned on.
Maybe, if you knew nothing about how lightbulbs and light switches worked, you might first try flipping all three switches. If you did this, you would receive negative feedback because, when you went into the next room to see which light was turned on, you would see all three turned on and learn nothing.
This is exactly how computers approach problems: they start knowing nothing. A machine doesn’t inherently understand that flipping a single switch turns on one lightbulb, just like it doesn’t know whether flipping a switch might cause a hurricane in the Atlantic. This lack of context in AI is termed the frame problem.
The causality mechanisms intrinsic (or learned…it’s still up for philosophical debate) in humans have to be learned by machines. This is what happens in ‘training.’
As data scientists, we are responsible for providing feedback, both negative and positive, to teach the machine not only the correct answers but also the problem they are trying to solve.
At the start, the model makes completely random guesses. It has no idea what it’s doing! But as humans, we design systems that measure how wrong the model is and tell it what to adjust to get closer to the right answer.
Once the model’s errors get small enough, or at least stop improving in a meaningful way, we say the training is complete. The model has “learned” the problem and its solution.
Fortunately, TCLP’s extensive library of clauses, guides, and glossary terms provided a solid foundation for text identification. But getting access to a database of real-world contracts? That was like asking a lawyer to hand over their billable hours for free.
Instead, we had to create synthetic data, a common practice in data science. Creating synthetic data involves generating artificial data mimicking real-world data. In this case, it involved creating an artificial dataset of contracts, some of which contained TCLP clauses or language modeled on TCLP content, while others did not.
We created this synthetic data by:
- Sourcing Public Contracts: We discovered the Security and Exchange Commission (SEC)’s EDGAR database, which hosts contracts submitted under public disclosure agreements. We used spelling differences as a proxy measurement for filings by British companies in a primarily American dataset, filtering the database to approximately 9,000 jurisdictionally-relevant contracts.
- Narrowing the relevant TCLP clauses: TCLP provides clauses for jurisdictions across the world. To align with the filtered SEC database, we segmented only those clauses applicable to England and Wales.
- Generating TCLP-inspired clauses: Since not all users input TCLP clauses into their contracts verbatim, we generated an additional 1,800 clauses inspired by TCLP style and content.
- Inserting real and generated clauses into contracts in context-aware manner: Based on semantic similarity between the SEC contracts and the real and generated clauses, we inserted the most relevant clause into 60% of the original 9,000 contracts.
Given the complexity and implications of steps 3 and 4, we will explore them in more detail.
Using a Large Language Model (LLM) to generate TCLP-inspired clauses
Our clauses are used in a variety of ways – most commonly as a tool to stimulate conversation and influence colleagues. But when our clauses do end up in contracts we know these are either with light edits, or used as direct inspiration for practitioners to write their own. So, in creating the synthetic database, we wanted some contracts to include TCLP verbatim content and other contracts to include content inspired by TCLP, to better reflect reality.
This meant we needed to generate additional clauses which feasibly sounded like something TCLP might write. To create this expanded set of synthetic clauses, we fine-tuned the GPT-3.5-turbo model using OpenAI’s API. We did this by turning TCLP’s content into a structured JSONL file the machine could understand.
What is a JSONL file and how is it used for LLM fine tuning?
When you interact with ChatGPT or any other Large Language Model (LLM) through a user interface, you are automatically assigned a role: the user. But behind the scenes, there are actually three key roles in this process:
- User – You, the person sending the prompt.
- System – The instructions that set the rules for how the model should behave.
- Agent – The specific instance of the model responding to your request.
Every time you, as the user, send a prompt, the system provides background instructions, like “You are a helpful AI assistant.” The agent then generates a response based on both these instructions and your input.
Most of the time, when you use an LLM through a chatbot, you’re relying on its base training data. This means it is great for general knowledge tasks but not so great for specific use cases like drafting legal clauses.
So, what if you need an LLM to be more tailored to your needs?
You have two options:
- Prompt Engineering – Giving detailed, structured instructions to get better responses without changing the model itself.
- Fine-Tuning – Paying to train a custom version of the model by providing new examples of how you want it to respond.
Using OpenAI’s API, we fine-tuned by giving the model a JSONL file where we played the role of system, user, and agent. We opted for fine-tuning over prompt engineering as it actually updates the model’s weights and biases, meaning it learned from the data we provided over time.
An example of one, of many, lines in the JSONL file:
{"messages": [{"role": "system", "content": "You are a helpful assistant that writes legal clauses."}, {"role": "user", "content": "Please write me a legal clause that could be integrated into a contract for Misleading environmental claims."}, {"role": "assistant", "content": "1 Greenwashing means misleading consumers, authorities or others by implying or making a claim, which cannot be verified, that an entity's products, services, activities, policies, business practices, processes or brands: (a) have a positive effect on the environment; (b) have no adverse environmental impact; or (c) are less damaging to the environment than a previous version of the product, similar products or competing products, services, activities, policies, business practices, processes or brands. [END]"}]}In our case, the ‘agent’ always responded with verbatim TCLP content. Therefore, through fine-tuning, the model learned the form and tone of TCLP content and could later reproduce content of a similar kind.
Once the GPT was fine-tuned, we performed a language analysis on existing TCLP data, identifying the 390 words that appeared most commonly (controlling for common words like and and the). Using permutations of these words in groups of three, we prompted the custom GPT 1,800 times.
For every prompt, the model returned a newly crafted clause, reflecting the same style and intent as real TCLP clauses. Here is an example, based on prompting with the words carbon, procurement, and scope 3:
“All procurement must support the achievement of the target OR align with the target for Net Zero by 2050 (including Net Zero by 2080 if a Developing Country, and 2050 for adaptation] and: (a) make source, transportation of source, and carbon intensity of the goods or services a key factor in procurement and (b) set and publish annual targets converted to carbon for Scope 3 Emissions that result from its procurement.”
The resultant clauses are imperfect, and would need more oversight before this type of process was used to generate clauses for actual use. But, for the inclusion in the synthetic database, to mimic the way TCLP language might be changed or interpreted, they were ideal.
Developing context-aware clause recommendations
In order to ensure the realism of these contracts, we did not want to insert just any clause into just any contract. Had we done so, we could have accidentally trained the model to identify language that feels out of place rather than learning to identify TCLP-inspired language.
Instead, we created another model, the “clause recommender” which would identify the clause, or generated clause, most applicable to a given document. We did this iteratively:
- First, we tested traditional approaches such as bag of words as well as slightly more sophisticated techniques like doc2vec. Both of these approaches rely on statistical representations of word frequency and co-occurrence within documents.
- Then, we tested LegalBERT, a fine-tuned Bidirectional Encoder Representations from Transformers (BERT), focused on legal documents, statutes, court decisions, and contracts.
- Each of these approaches outputted those clauses that were most likely relevant to the provided contract. Finally, we gave all three results to a legal expert to assess. Although randomised and unidentified, she consistently chose the recommendations given by LegalBERT as the most relevant.
What is LegalBERT?
LegalBERT is a deep learning model based on transformers, a type of architecture introduced in the seminal paper *Attention Is All You Need.* Instead of just spotting keywords, transformers analyse the context of a piece of text using something called self-attention. This means LegalBERT doesn’t just recognise words; it understands how they relate to each other across a contract.
For example, think of a situation where a contract and a clause both contain the word “liability”. The clause might be something like Connor’s clause, which concerns insurance liability for climate-related claims. Meanwhile, the contract could be focused on software liability, addressing risks such as data breaches and service outages. If a clause recommender relied only on keyword matching, it might incorrectly suggest Connor’s clause for this contract simply because both reference “liability”. The self-attention mechanism allows the clause recommender to consider the surrounding context, recognising that the contract deals with technology-related liability, not insurance.
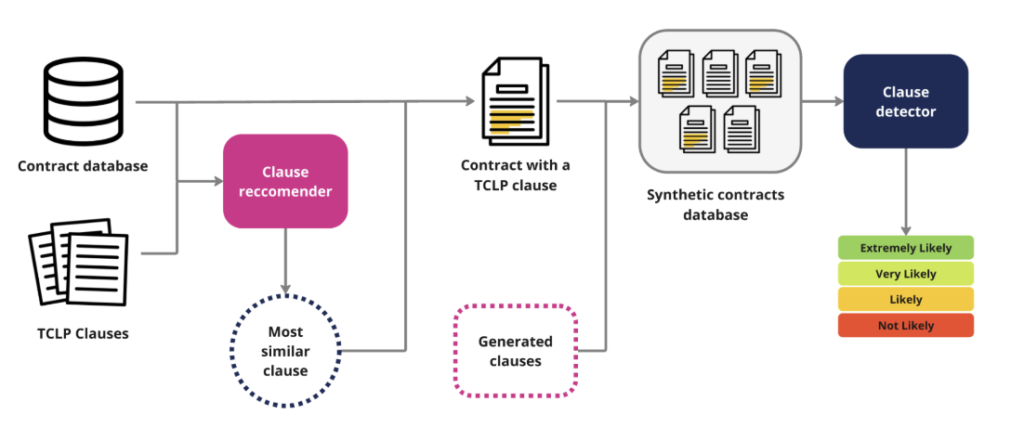
Bringing it all together: creating the synthetic data
With the clause recommender in hand, we now could create a synthetic database. Starting with the 9,000 SEC contracts, we used the clause recommender to assess each contract, and recommend the most similar clause. This clause could be either a TCLP clause (from England/Wales) or a generated clause. 60% of the time, the identified clause was inserted. The other 40% of the time, the contract remained untouched.
Model development
Using the synthetically created database, we began training another model to detect clauses across a contract database (herein termed the “clause detector”). This involved several key NLP techniques:
- TF-IDF Vectorization: Transformed contract text into feature vectors by assigning weights to terms based on their frequency in a document relative to their frequency across all documents.
- Classification Model: Used logistic regression for binary classification at the sentence level, determining whether each sentence contained TCLP language.
- Multi-class Classification: Implemented thresholding to extrapolate sentence-level results to entire contracts, categorising documents as “Extremely Likely,” “Very Likely,” “Likely,” or “Not Likely” to contain climate-aligned clauses.
What does “TF-IDF vectorization” mean?
TF-IDF stands for Term Frequency-Inverse Document Frequency. It’s a statistical method used to transform text into numerical features based on word importance. It helps identify how relevant a term is within a specific document, relative to a larger collection of documents (the corpus). Let’s break it down:
It’s a relatively simple approach but foundational to NLP, the broader field that encompasses modern Large Language Models (LLMs) like ChatGPT.
TF-IDF gives each word a score, so it can be represented numerically, as numbers are the language of computers.
- Inverse Document Frequency (IDF): A measurement of how often our ‘term’ appears in the general corpus. And then flipping that importance so that if a word appears in lots of documents, it is given a lower weight. Think of words like like the or and. If a word only shows up in a few places, it’s likely more characteristic of this specific document and therefore given more weight.
- Inverse: Taking the opposite of something (kinda; for simplicity).
- Document: A single text within a larger collection.
- Term Frequency (TF): The number of times a term appears in a document, normalised to account for document length.
- Frequency: How often that term appears in a given document.
- Term: A word or phrase being analysed.
At the sentence-level, the model achieved an accuracy of 97% when assessed on the test set. However, that was not the question we set out to answer. Using multi-class thresholding, the model achieved an overall accuracy of 94% when categorising an entire contract.
With the clause detector model, 1,000 documents can be analysed in under a minute.
Technical testing and validation
Testing methodology
Throughout the project, we placed a premium on validating our work using methods such as:
- Expert Validation: An expert lawyer assessed the clause recommender’s outputs, consistently choosing the recommendations from LegalBERT as the most relevant when presented with randomised, unidentified options from different models.
- Holdout Testing: The models were trained on 75% of the data (6,555 contracts) and tested on the remaining 25% to evaluate performance.
- Performance Metrics: The clause detector achieved 97% accuracy at the sentence level and 94% accuracy at the document level.
- Error Analysis: Even false positives proved encouraging, as they primarily consisted of climate-related language already present in the EDGAR database, indicating that the model had learned to identify relevant patterns rather than simply matching predefined labels.
The promise of false positives
Even the occasional false positives were encouraging, as they primarily consisted of climate-related language already present in the EDGAR database. These false positives indicate the model did not learn to identify discordance and did learn to identify TCLP or TCLP-aligned language.
For example, this is one “false positive”:
The Tenant shall use reasonable commercial efforts to comply with any measures the Landlord, acting reasonably, or any legislative authority may from time to time introduce to conserve or to reduce consumption of energy or to reduce or control other Operating Costs or pay as Additional Rent the cost, to be estimated by the Landlord, acting reasonably, of the additional energy consumed by reason of such non-compliance.
This text is not labeled as TCLP-aligned, as it was not inserted manually. It was already present in the underlying data. That said, it contains language strongly related to climate considerations. This “false positive” indicates that the model successfully identified relevant patterns rather than simply matching predefined labels.
Results and findings
The clause detector achieved impressive performance metrics:
- 97% accuracy at the sentence level
- 94% accuracy at the document level when using multi-class thresholding
- Ability to process 1,000 documents in under a minute
Notably, when the same task was given to an industry-leading Legal AI chatbot, it performed with less than 50% accuracy, demonstrating the value of the targeted approach.
Design process
When working at pace and innovating a minimum viable product, it’s easy to overlook or completely neglect the user experience of it, especially when working with emerging technology. In such cases, the primary question often becomes “is this technically possible?” rather than “is this valuable to others?”.
With working and accurate models in hand, we faced our final challenge: how could we transform this tool—currently limited to individual laptops and run via command-line interface—into an accessible, user-friendly product for non-technical users? Doing so would not only serve as a way to provoke thought and gather valuable feedback from our network, but also indicate if the solution was scaleable and useful to others.

View the user journey in more detail

Design principles we followed:
- Keep the content clear: we used everyday words, and avoided any technical language (higher literacy people prefer plain English too). We even avoided the temptation of using our internal “detect” or “recommend” framing, and instead opted to name the features based on the task. For example “Check if your contracts are climate aligned”. This makes it universally accessible, and opens the audience to non-native English speakers too.
- Function over form: we used common UI components and standard aesthetics, because it’s important that the UI felt familiar, even boring, regardless of the fact we were using cutting edge technology under the surface. Flashy interfaces are best saved for the movies.
- Make the process visible: we’re asking the users to do something quite new with very sensitive documents, so it’s important they understand what’s going on and feel in control. This means breaking the process down into clear and focused steps – and where possible – expose the logic in an accessible way.
- Make the results relatable: the maths behind the results are crucial, but very few people will have the time or skills to understand these. We opted for a basic ranking system and where necessary explained this in simple terms.
Feature spotlight: helping users find and filter ~170 clauses 2 seconds
As we approached the conclusion of the proof-of-concept stage for the clause detector, we were excited to realise that the clause recommender we had developed as part of building the synthetic database could also provide benefits for users as a standalone feature.
Currently users have to search, filter and browse through ~170 clauses to find the most relevant one, which requires a great deal of time, patience, and luck from the user. The clause recommender could behave like a sommelier; gathering the requirements of the contract and bringing back a short list of clauses for the user to consider.

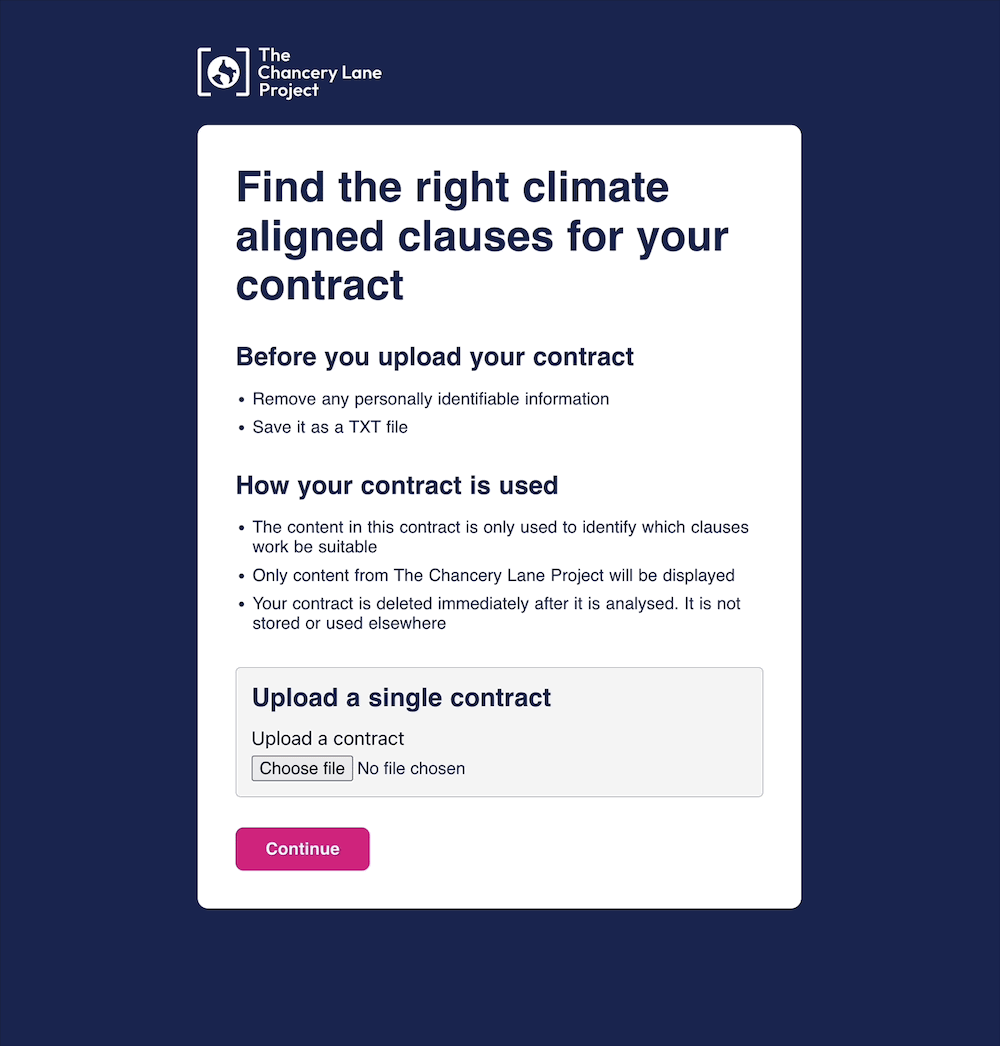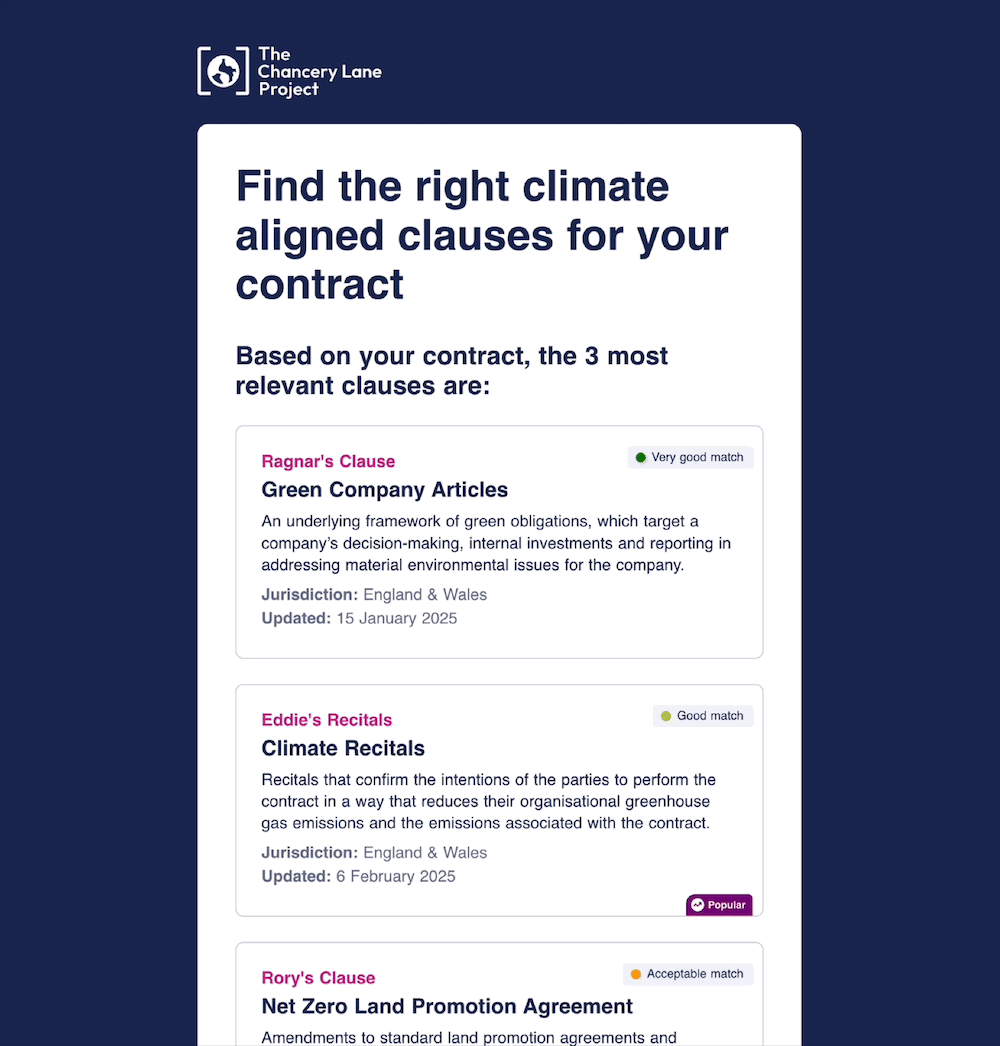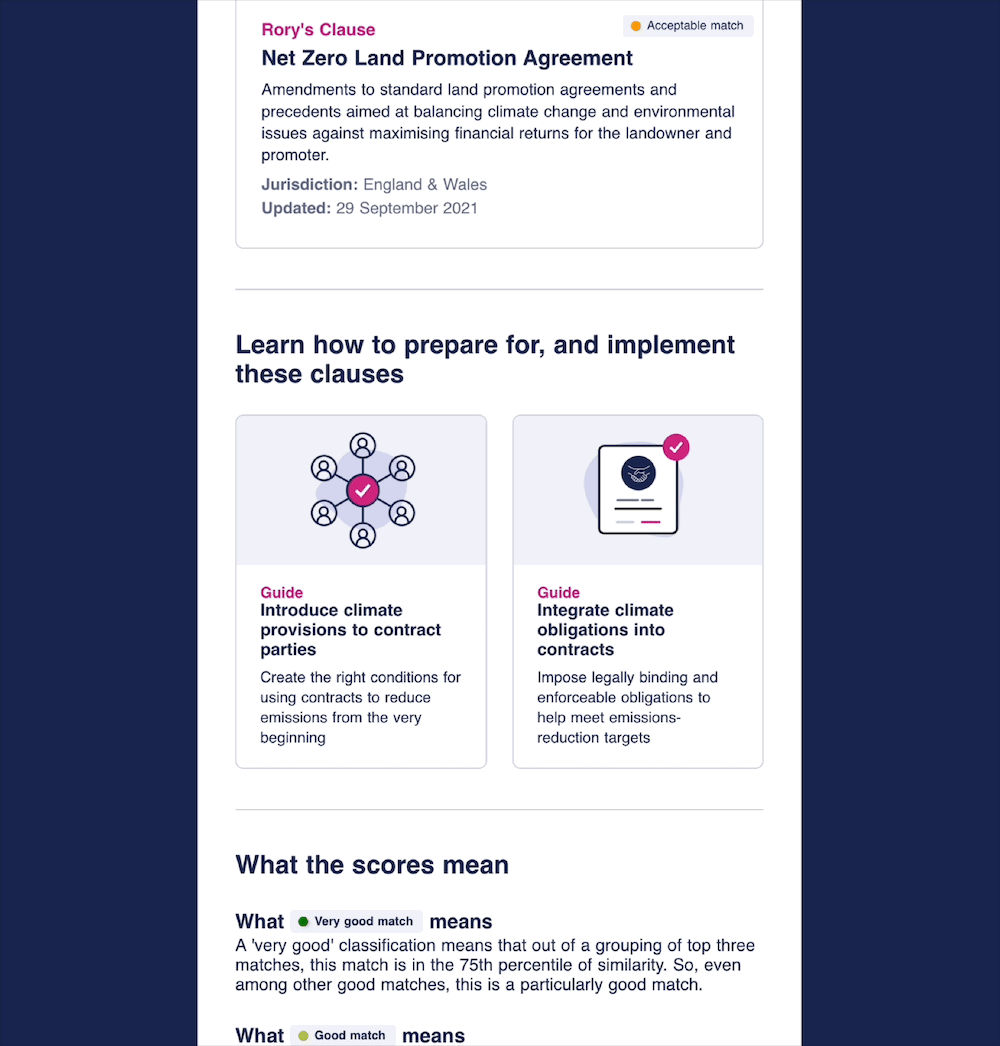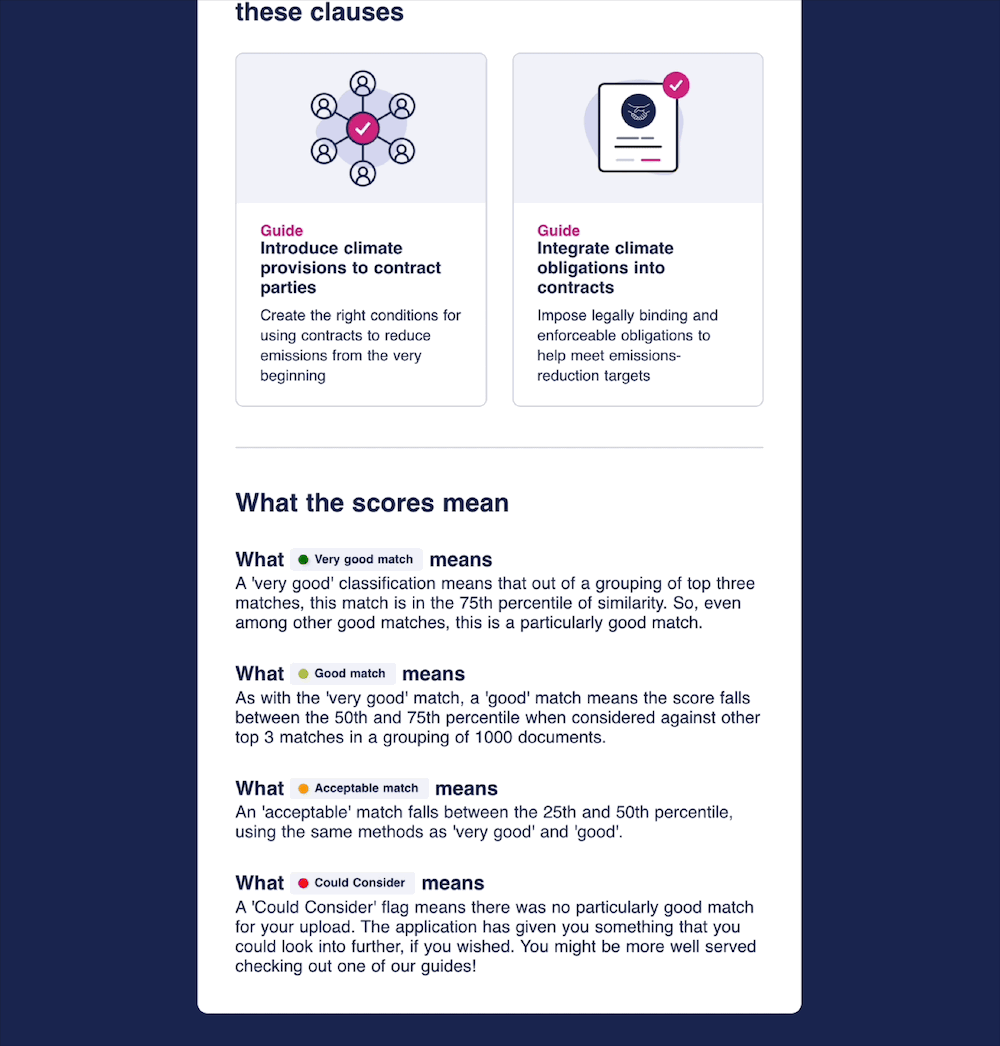
View the user journey in more detail

The recommended clauses were classed based on the model’s similarity score with categorisations ranging from ‘very good’ to ‘could consider.’ Scores range from 0 to 1 with scores closer to 1 indicating stronger matches.
To determine thresholds for each category, we analysed the top three matches for a thousand different contracts and plotted their similarity scores on a normal curve. It’s important to note that this normal distribution only includes the best matches for each contract, meaning even lower-ranked scores represent potentially meaningful connections.
The categories were assigned as such:
- Very Good Match (≥ 0.91) → Clauses in the 75th percentile or higher
- Good Match (0.89 – 0.91) → Clauses ranking between the 50th and 75th percentile
- Acceptable Match (0.82 – 0.89) → Clauses falling within the 25th to 50th percentile
- Could Consider (< 0.82) → Clauses in the bottom 25th percentile, still relevant but less strongly aligned
Making sophisticated software useable and accessible is crucial step in understanding if it’s valuable for a wider audience, or simply a fun technical experiment. Software powered artificial intelligence is no different.
Considering the climate
In addition to carefully considering the energy impact of this work—detailed and visualised here—we prioritised an approach that started with the least intensive method and scaled up only when necessary.
As artificial intelligence becomes a buzzword, there has been a backlash against traditional machine learning approaches. Many companies push for AI simply for marketing purposes, eager to claim they are using the latest technology. And AI can be a powerful tool but sometimes using a blender when a whisk would have worked just fine entails a worse output and more energy usage along the way.
Responsible practitioners take an iterative approach, as demonstrated in the development of the clause recommender. Simpler models were tested first, and only when they failed to produce sufficient results did we move to a deep learning-based approach.
For the clause detector, a traditional machine learning model proved to be the most effective solution, achieving 94% accuracy. For comparison, when we gave the same task to an industry-leading Legal AI chatbot, it performed the same task with less than 50% accuracy. The chatbot, as a generative LLM, would have used significantly more resources, both in training and in usage, for a worse result. While AI and LLMs are undeniably powerful, there are still many cases where traditional machine learning approaches, such as TF-IDF and logistic regression, remain the best tools for certain jobs.
Consciously considering one’s tools, and their environmental implications, should be the standard for data scientists. Companies that naively and incessantly push for “AI at all costs” risk solutions that are potentially worse for their results and the planet.
I am very grateful that TCLP did not have those ulterior motives and were happy to proceed with the best solutions, not the most trendy ones.
Georgia Ray
Ultimately, we deployed two models—one would typically be described as artificially intelligent, a deep learning approach. The other is a classic machine learning model. We used generative AI only in the creation of the synthetic database, and did not embed it into processes. This one-time usage ensures lower environmental impact as generative AI is the most energy intensive.
Lessons Learned
Technical insights
Key technical insights included:
- Appropriate technology selection: The project demonstrated that traditional machine learning approaches can sometimes outperform more complex deep learning models for specific tasks. The clause detector achieved 94% accuracy using TF-IDF and logistic regression, while an industry-leading Legal AI chatbot achieved less than 50% accuracy on the same task.
- Environmental considerations: We prioritised an approach that started with the least computationally intensive methods and scaled up only when necessary.
- Data challenges: The lack of access to real-world contracts containing TCLP language necessitated creative approaches to data generation, including the use of synthetic data and fine-tuned language models.
- Model selection: Different tasks required different approaches. The clause detector performed best with traditional machine learning, while the clause recommender benefited from a transformer-based approach that could understand context and relationships between words.
Process insights
Process insights included:
- Iterative development: Testing simpler methods before moving to more complex ones proved effective, ensuring that resources were used efficiently.
- User-centered design: Transforming technical capabilities into user-friendly tools was recognised as crucial for understanding the value of the technology beyond technical experiments.
- Collaboration: The project benefited from collaboration between technical experts and legal professionals, with expert validation playing a key role in assessing model performance.
What’s next
With both models functioning and deployed, the name of the game is improvements. We plan on doing this through in a number of different ways:
- Continuous improvement: Staying appraised of the latest developments in data science and machine learning to refine the tools, making them more sustainable and effective.
- Private Beta access: We have given private access to the tools to selected law firms and prominent technology companies in the legal domain. By doing this, we’ve gained valuable feedback as to their current form and future direction. Broader Beta testing will allow us to identify potential weaknesses, fix issues, and gather further real-world feedback to enhance future model training.
- Security enhancements: Another key priority is integrating encryption throughout the process. Until now, we have worked exclusively with publicly accessible content, but to extend these tools to organisations like law firms or corporations, data security will be essential.
You can access the code behind the tools on GitHub, and if you’d like to be involved in Beta testing, drop us an email on [email protected].